文字探勘旨在使用資訊科學發展出來的數學演算法,進行文本資料的分析。所謂探勘指由資料導引(data-driven) 的一種資料探索。剛開始可能只有一些靈感或懷疑、未必有明確的理論導引,探勘的重點是發現,歸納所有資料得到的整體趨勢或律則,這個趨勢或律則套用在個別的事件上,肯定會有落差,但卻有良好的解釋與預測功能。當然,這個發現是不有意義,要由研究者自己判斷,電腦不可能代勞。有了研究發現,研究者可以回過來檢討演算法,或者與其他資訊比對,解釋其原因與發展脈絡。基本精神是「一切讓資料說話」,雖然一開始它沒有明確的理論指引,然卻有建構理論、開拓視野的可能性。
我們的研究對象是大陸官方出版的人民日報,人民日報自1946 至今,累計大量文章,我們要如何針對這巨量文本進行探索性分析呢? 傳統人力閱讀的方式顯然不合適。由程式進行探索有許多好處。首先是速度快,可以節省大量的時間、人力,讓不可能變成可能。但問題也在這:電腦不是真正意義的「閱讀」,也不是真正的「思考」,它只是輸入(import)大量資料,然後進行繁複的計算與比對,得出結果(output)。計算出來的結果,有什麼意義? 可以用在哪? 電腦不知道,這要由人來判斷。因此,計算的流程或演算法的選擇就非常重要了。演算法是一組特定的計算程序,旨向某個特定目標,這個目標通常是為了符合數學上分析的需要。以下,我們介紹文字探勘基本的操作流程,並思考它們在探索人民日報上可能扮演的角色。
文字探勘與傳統文本分析的本質上差異,略述如下:
- 文字變成向量:
- 社會科學的探討離不開文本,與傳文本析最大的不同是,文字探勘把文字變成向量,變成研究者無法識別的代碼或符號,再利用數學演算法尋找規則,找到規則後再還原成文字,接著,研究者方能解釋這些規則的意義與應用。而傳統的文本分析,著重於文章、字詞、語意的理解,研究者的洞見靈感、經驗(功力),以及語意、語境的掌握,有不可或缺的重要性。文字探勘反其道而行,這些反而變得不重要了,這是首先必要注意的。
- 海量資料與整體趨勢:
- 正因為文字探勘把文字變成向量,利用演算法找規則,它可以處理海量的資料,例如人民日報從1946至今,近兩百萬篇文章,人們無法逐一閱讀,電腦卻可以。同時,也正因為如此,文字探勘主要是尋找文的整體趨勢,而非針對若干文本的細緻分析與比對。若研究者關心的是後者,顯然傳統的研究方法較有效。
- 樣本即母體:
- 由於文字探勘處理海量的資料,它沒有樣本與母體的差別。樣本即母體,無統計推論 P- value 顯著性的問題,替代是預測準確率的概念,亦即衡量找到的規則或模型是否有效。所以文字探勘的研究發現僅適 用於與分析資料類同(同性質)的文本,對不同性質的外部文本是無法推論的。
- 資料導引:
- 文字探勘從資料找規則,這是資料導引(data driven) 的研究途徑,它與傳統的量化研究,理論導引(theory driven),再驗證理論的取徑不同。研究者基於不同的研究目的,自然會有不同的取捨。不過,雖然沒有理論導引,探勘時還是要有清楚的問題意識,以此界定探勘的範圍,比較會有成果。
- 長於預測,拙於解釋:
- 文字探勘與大數據分析一樣,基本上它長於預測,但拙於解釋,它只是嘗試尋找一些現象,這些現象可能學界早已熟知,也可能意外突兀、不明所以,就探勘而言,這些都是有意義的,特別是它的突兀發現,有可能開拓另一個新的問題意識或研究領域。
- 視覺化:
- 由於分析的過程都仰賴量化的演算法,文字探勘有一個很好的長處,它可以視覺化所有的研究發現,研究者可以更有效的掌握最後的結果。
- 思考輔助工具:
- 文字探勘是很好的思考輔助工具,它可以幫助研究者「思考」,但無法替代思考。它的研究發現,經常出人意表,然而其意義與適用性,還是得靠研究者主觀詮釋。另外,由於計算繁瑣,需耗用大量記憶體,除了程式寫作之外,運算速度常經常也是瓶頸。
- 資料科學:
- 由於文字探勘是由資料科學(data sciences) 發展出來的分析方法,社會科學研究者通常不具備開發演算法的能力,因此學術合作無可避免,然不同領域,溝通不易,因此,基本的程式能力還是需要,同時使用演算法時,要瞭解其基本邏輯,方能正確解讀結果,這也很重要。
文本前處理
我們取得電子化的文本資料,通常是doc, txt, html, csv, xlsx 或 pdf 等格式 (圖像檔jpg, .mpg 等則不行)。首先,這些文字檔轉為 txt 格式,亦即沒有其他格式設定的純文字檔。如果是中文資料,中文編碼模式可能不同,我們以通行的utf-8 格式為主,中文編碼統一為 utf-8 格式,以利後續讀取資料。格式確定無誤之後,前處理的第一步是刪除不必要的特殊符號,這些大多是版面控制指令或代號,因為它與文本語意無關,避免干擾,最好先刪除。
文本資料清理乾淨了,接著要處理「斷詞」的問題。中文的文意以「詞」為單位,「詞」由「字」所組成,但「詞」產生之後,經常脫離了「字」的原始意義。例如,「鄧小平痛下決心要改革開放」這句話。其語意是:「鄧小平_痛下決心_要_改革_開放」,每個詞都有特定意義,拆開來意義就不一樣了。因此,斷詞很重要,因為詞才是基本的語意單元。一般我們閱讀文章,人的大腦憑經驗會自動斷詞,不會防礙文意理解,電腦就不行了。我們要給他斷詞規則,每個詞就電腦而言都是個「符號」,電腦會將每個符號編碼、記住它與字詞的對應關係,然後進行複雜的比對與計算。
斷詞的工作,我們採用 Jieba 配合python3程式來處理,這些都是免費共享軟體,使用方便。不過,結巴斷詞時有錯誤,其原因可能是新詞彙無法識別,例如「九二共識」、「長照」、「去中國化」等,也可能是人名「陳建仁」、「阿扁」,也可能是特殊的用語如「兩千三百萬」,這些新生的字詞,也許使用尚不夠普遍,結巴未必能識別,因此造成斷詞錯誤。另外,有些斷詞的錯誤是語法模糊引起的,例如「中國電視台獨家報導」可以斷成:「中國電視台_獨家_報導」或「中國_電視_台獨_家_報導」。就人腦而言,很容易辨別對錯,但就電腦而言,就是很大的挑戰。碰到這種問題,我們可以用增加新詞彙,或者用人工校正的方式處理。
字頻、詞頻、詞對與共現性
文本經過斷詞之後,就可以進行基本的字詞計算。字詞如果出現愈多,應該代表意義愈大,一般是如此,但非絕對。字詞計算有字頻、詞頻、詞對等,略述如下:
- 字頻:以字為單位,統計出現的頻率。此時會發現標點符號,之、乎、者、也、的、了、麼、而等虛詞出現的頻率會特別高。
- 詞頻:以詞為單位、統計出現的頻率。這比單純計算字頻意義多了,不過,我們仍然發現一些沒有意義的慣用語仍然頻率偏高,例如而且、那麼、以及、然而、但是、亦即、不過等出現的頻率特別高,但對我們理解文意卻幫助不大。
- 詞對:詞對是計算詞與詞間的共同出現的頻率或機率。例如:毛澤東與偉大、領袖、領導、鬥爭、革命等詞彙經常共同出現,顯然這些字詞有某種直接或間接的關係存在。除了計算頻率外,也可以計算卡方值,顯示共現的強弱。詞對分析經常可以結合語料庫,語料庫是一組依特定目的而建構的詞彙集,例如我們把所有與「情感」有關的語彙聚集在一起,然後看「毛澤東」與「情感語彙」間的共現關係,就可以看出人民日報對毛澤東的評價了。
字頻、詞頻、詞對顯示文本的特某特質,比較不同類型、時間、來源文本的差異,經常會有有趣的發現。
自然語言處理
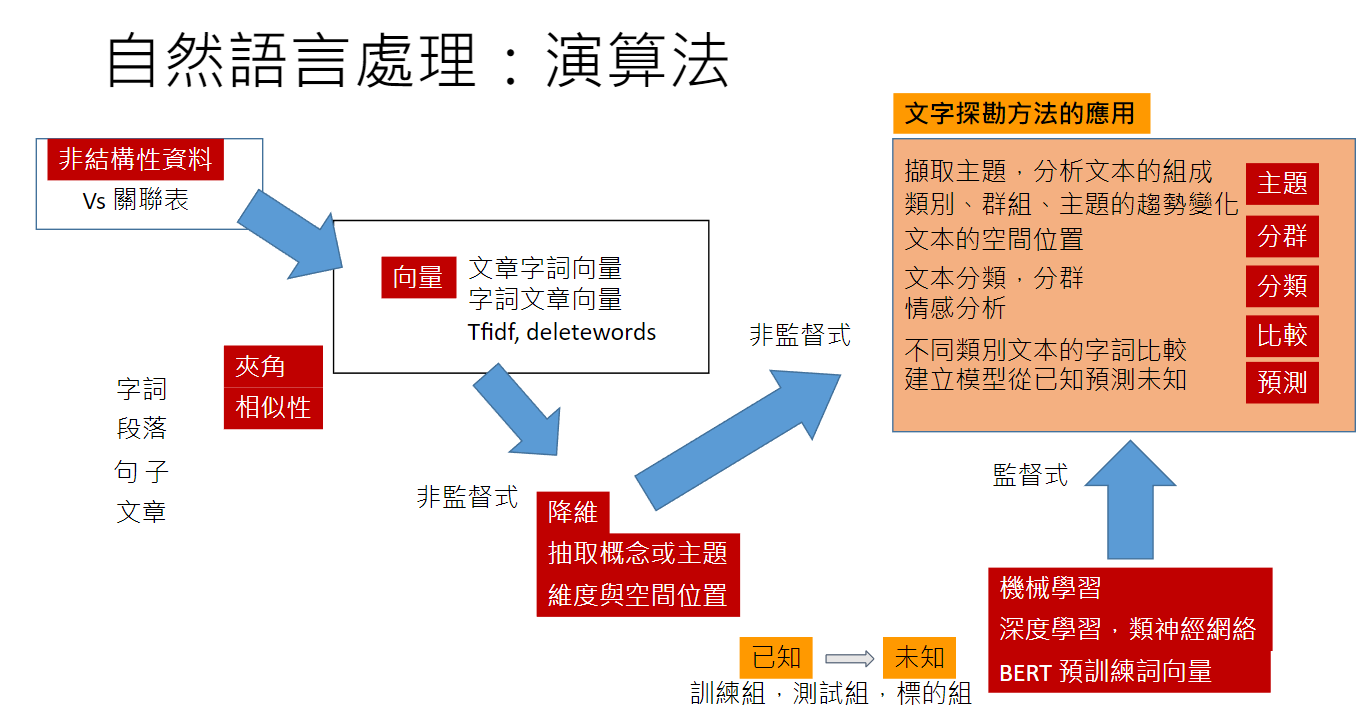
前述字詞的計算,字或詞都是一個符號或代碼,符號和代碼本身並沒有意義,自然語言處理想要賦予這些沒有意義的東西「意義」。基本的做法是讓字詞變成一個高維度的向量。在向量空間中每個字詞都有一個位置,向量有長度、彼此之間有夾角,更重要的是向量化之後,文字變成數字,可以進行數學計算,例如相似性、降維、分佈、核心點、平均、分群、分類等。
向量化的方式有許多種,最傳統的做法是製作「字詞-文章」向量。亦即做一個矩陣,列(rows)為每一個字詞,欄(columns)為每一篇文章,構成一個高維度的矩陣,例如人民日報有二十萬個字詞,有兩百萬篇文章,這就是一個兩百萬乘二十萬的巨型矩陣。矩陣內的元素,代表字詞在文章中出現的個數。如此,每個橫列代表某個字詞的向量(term vector),維度為兩百萬。同樣地,我們也可以製作「文章-字詞」向量,每個橫列代表某篇文章的向量(document vector),維度為二十萬。如此,文章的向量與字詞的向量就被定義出來了。
文章的屬性,由字詞依不同的權重所構成;同樣地,字詞的屬性亦由文章依不同的權重所構成。向量中的數字愈大,代表該對應的字詞或文章愈重要。不過有例外,舉例來說,一個文章矩陣,某個詞 A 廣泛的出現在許多文件中,而另一個詞 B 卻只出現在少數特定的幾份文件中,而檢查某一篇文章,發現詞 A 與詞 B 出現的次數一樣多,我們可能說就這篇文章而言,這兩個字詞有同樣的重要性嗎? 不行! 詞B 更有意義,詞 A 可能是一些沒有意義的虛字,例如「的」、「了」、「而且」、「以及」、「然而」、「亦即」、「當今」等,這種字詞在每篇文章都出現,但無助於我們瞭解文意。為了解決這個問題,就要使用文字加權的技巧了。常用的方法是 TF-IDF(Term Frequency – Inverse Document Frequency) 主要精神是降低普遍都會出現的字詞的權重,同時,各字詞出現的頻率要除以文章總字數,排除文章長短造成的影響。綜合這兩個指標,設定字詞的權重。當然,我們也可以把那些沒有意義的「虛詞」事先就刪除(視為停用字),可以達成同樣的加權效果。
以上的做法,我們統稱為「文字袋」(bag of words),亦即一篇文章就是一個文字袋,我們把文字符號,組合在一起,放在袋子裏,袋中有什麼東西很清楚,但是順序不重要。「毛澤東-發動-文化大革命-鬥爭-劉少奇」與「文化大革命-發動-劉少奇-毛澤東-鬥爭」就文字袋來講都是一樣,我們假定語意都一樣。我們也可以標記文字袋內字詞的「詞性」,例如發動是動詞,文化大革命是名稱,毛澤東、劉少奇是人名。文字袋內的東西有了屬性,資訊更豐富,更貼近真實世界,採討的方式也更多元,但本質上,這仍是「文字袋」,向量化的過程當中,字詞順序被忽略了,這是很大的缺陷。這個問題在類神經網絡(後面會介紹) 裏獲得部分的解決。
降維、相似度與分群與主題分析
當字詞與文章都變成向量,就可以計算向量與向量之間的相似性。空間裡的兩個向量,當夾角愈小,兩向量的差異愈小;夾角愈大,兩向量的差異愈大,因此,兩向量的相似性定義為夾角θ的餘弦(cosθ),其公式為向量的內積除以兩向量的長度。除了相似度的計算外,還可以做許多更複雜的處理。不過,字詞向量與文章向量維度太大,嚴重影響計算的速度,降維( dimension reduction)乃成為必要的手段。
文字探勘常用的降維技巧是奇異值分解(SVD)或主成分分析法(PCA)。這與統計學上因素分析的邏輯類同,主要用來進行向量間的整併。其原理是找尋幾個彼此獨立的向量 (或稱「軸」),所有字詞向量或文章向量在各軸上的投影,我們希望總共的投影值要極大化。向量在各軸上的投影值構成新的向量,其維度就是軸的數目,如此原來數萬維的向量,可以降至少數幾維。當然,降維的過程中有不少資訊會散失,這是個兩難,維度降低愈多,散失的資訊也愈多。我們找到的這幾個「軸」,也有意義。「軸」本身是高維度的向量,我們稱之為「組成」(components)。文章字詞矩陣,降維後,「組成」稱之為「概念」(concepts)。概念內的字詞,依其貢獻度高低排序,就可以知道概念代表的意義。也就是說,每一篇文章都是由幾個不同的「概念」,依不同的比重(投影量) 所構成。
同樣地,字詞文章矩陣,降維後,每一個字詞在各「組成」上都有投影。也就是說,每一個字詞都是由幾個「組成」,依不同的比重(投影量) 所構成。由於每個字詞都是一個向量,我們可以計算最接近的字詞,或最接近的幾個字詞,這與我們前面提到的「共現性」類同,尋找最「接近」的字詞。最「接近」的意義就是在文章中共同出現的可能性。
透過降維的方式可以達成萃取「概念」的目的,這種方法一般稱為LSA, latent semantic analysis,即潛在語意分析。還有其他演算法,例如 NMF, LDA,其目的都是要尋成文章的「組成」,各文章均由這些「組成」依不同的比重所構成。這些比重代表投影值的大小,它也可能是機率的概念,加起來是百分之一百,例如 LDA 演算法就是這樣,這些尋找「組成」的方法都叫「主題分析」 (topic model analysis)。每個主題都有特定的意義,在人民日報的研究中,我們可以理解為「框架」。主題代表不同的框架,因為如果框架相同,文字的結構會有較高的相似性。
另一種做法是,事先預想有幾種報導的框架,再以人工的方式找出幾篇代表該「框架」的文章當作標的。接著計算所有文章與框架標的相似性,達一定標準者(例如 80%) 就可判斷為屬於這個框架。這也是假定同樣的框架,文字結構必定類同。
分群(clustering)是另一種常見的技巧。向量與向量間的相似度計算出來之後,比較接近的向量歸為一群,如此同類型的文章就會被歸為一群,不同的文章分屬不同的群,與主題分析不同的是,分群有排他性,文章只能屬於一個群,不可能同時屬於不同群,主題分析則無此限制。
由於人民日報有時間的屬性,觀察不同年度、時期、領導者的主題、概念、框架、分群,可以瞭解時間的變化趨勢。可以挑選單一的主題看它的時間變化,也可比較不同主題,或者比較不同時期各主題的佔比。如此可以探討的層面就很廣了,例如瞭解人民日報如何看待台灣?對政治領導者的不同評價?對美國、日本、西方列強的態度?對傳統文化、馬列主義、民主自由的不同看法? 等。
機械學習與分類
機械學習(machine learning)是電腦演算法最引人注目的貢獻。它不是單一的方法,而是多種演算法的的總稱,應用到不同的領域。基本上,他是從已知資料,找出準則,檢測其有效性、再應用到未知資料的一套流程。已知資料可以用 Y和X 來理解,Y是依變數,X是自變數,均是高維度的向量;未知資料則只有 X 沒有 Y。演算法是要從已知資料找出準則,再驗證準則的正確性。如果正確性令人滿意就可以套用到未知資料進行預測了,這是由已知預知未知,一般稱為「監督式學習」。
「分類」是機械學習最最基本的應用。此時 Y 是類別,兩個類別或多個類別。例如我們熟知的情感分析就是正、負兩個類別,當然也可以是多個類別,只要有屬性資料 X 就可以進行預測。值得注意的是大數據分析與傳統的統計最大的差別是,它沒有樣本與母體的觀念。所以也沒有統計推論,沒有 P-value,或犯錯的機率,取而代之的是準確率的估算,基本的做法是已知資訊分為訓練組與測試組,訓練組找到的準則套用測試組上,看看準確率有多高,而找準則是成敗的關鍵。由於資訊科學的進步,各種演算法推陳出新,廣為熟知的有Nearest Neighbors、Linear SVM、RBF SVM、Gaussian Process、Decision Tree、Random Forest、Neural Ne、AdaBoost、Naive Bayes及QDA等。這些演算法都有已經寫好的模組可用,不必自己寫程式。只要瞭解其構想,多些測試,即能找到最有效的演算法。
類神經網絡
類神經網絡(Artificial Neural Network)或稱深度學習(deep learning)則是近年大放異彩的機械學習演算法,在許多領域都有令人驚艷的表現,例如語音、圖像辨識、翻譯、聊天機器人、商品推薦、自動駕駛、專家問答、自動生成(創作)等等不勝枚舉,AlphaGo 圍旗打敗世界冠軍的故事更膾灸人口。
他的基本原理是字詞經過複雜,多個層級的神經元與參數的運算,得出預測值,和已知值比較差異,以梯度下降的方式,回頭去調整參數,如此遞迴進行,逐漸減小差異,值到穩定,新參數取代舊參數,模型訓練完成。由於訓練的資料量龐大,要不斷遞廻計算,頗為耗時,對記憶體與電腦設備的要求也很高,自己訓練有一定的難度,常常因為訓練資料不足,而效果欠佳。
類神經網絡雖然應用廣泛,就我們而言,則只關心與文字探勘有關的部分。最常見的兩種應用:字詞向量化 (word embedding )與分類。如前所述,訓練需要巨量的文本,且頗為耗時,幸好,網路上可以找到一些訓練好的模型,這是各研究團隊蒐集大量的文本,如維基百科、報章雜誌、期刊論文等訓練的成果。利用這些預訓練模型,可以將我們自己的文本轉換為向量。這是很了不起的貢獻,節省後學者大量的時間。但是,如果想要自己訓練,仍然可以利用 word2vec和 doc2vec 訓練自己的文本,其效果通常會比文字袋、降維的方式好。因為這些演算法都有考慮字詞順序的問題,字詞順序更動,形成的向量就不一樣。類神經網絡,配合預訓練模型,進行文本分類,效果非常好,這對我們而言很重要 。
文字探勘的限制
如前所述,結合大數據演算法之後,文字探勘讓有了嶄新的風貌。人民日報雖然高達兩百多萬篇文章,但是交由電腦處理,數量不是問題。重點是要有好的切入點 (研究靈感還是很重要) ,找到合適的演算法(這需要經驗),才能找到有趣的研究發現,接下來則是研究者的詮釋與反思。
文字探勘與電腦結合之後,雖然潛力無窮,但是有些先天的限制不能不知道。
首先它從詞頻出發,每個字詞就電腦而言都是個符號,電腦只是比對這些符號的頻率與關聯性,並不明瞭符號代表的「意義」。
事實上,人們使用文字,其定義不是那麼明確,不同地區、時期的用法可能不同,電腦無法區別這種差異,只是當成同一個「符號」來處理。更麻煩的是人們使用文字,基於某些目的,經常會故意扭曲其原始意義,意在言外,話中有話,看似褒實係貶。有時為了創造文學的美感,使用不同的辭彙,其實意義雷同;有些則是異體字的問題,繁簡混用,就電腦而言,不同的符號,代表不同的意義,它無法分辨這樣的差異。
文字探勘是透過大量的資料找尋律則或整體的趨勢,文本間的細微差異,並非重點。訓練的過程中,所有的文本都一視同仁,雖然可以透過篩選文本,汰除不要資訊,但留下來的文本貢獻度都一樣。另外,文字探勘無樣本與母體的概念,樣本即母體、母體即樣本,訓練資料與預測資料必須同質, 否則預測的結果,難保正確。
就本研究而言,我們希望瞭解中共意識形態的變遷,重要關鍵字的詞頻、詞對計算,及其歷年的變化都很重要。與傳統的框架分析接軌,萃取主題、分群、分類、機械學習都是重要的技巧。類神經網絡、文字探勘晚近的發展值得我們注意。以下幾個方向,是我們主要的分析策略。
- 以關鍵詞定義中共意識形態型的內涵,觀察其變化趨勢。
- 針對中共常用的政治術語,進行詞對、及潛在語意分析,探討其代表的意涵。
- 不同時期的文本比較,特別是比較習近平執政之後與其他各時期的差異。
- 針對不同主題或框架的探討,與政治環境脈絡的互動。
- 針對特定人物或事件的情感分析,解釋其差異。
- 中共對台的政治態度,特別是晚近的變化。
- 聚焦於特定的政策議題,探討中共的思維邏輯。
我們希望透過以上這七個策略,策略拼湊出中共的世界觀,他們是怎樣看待世界的,如何因應世局的變化。這其間肯定有不變的部分,也有變遷的部分,這會是我們討論的重點。