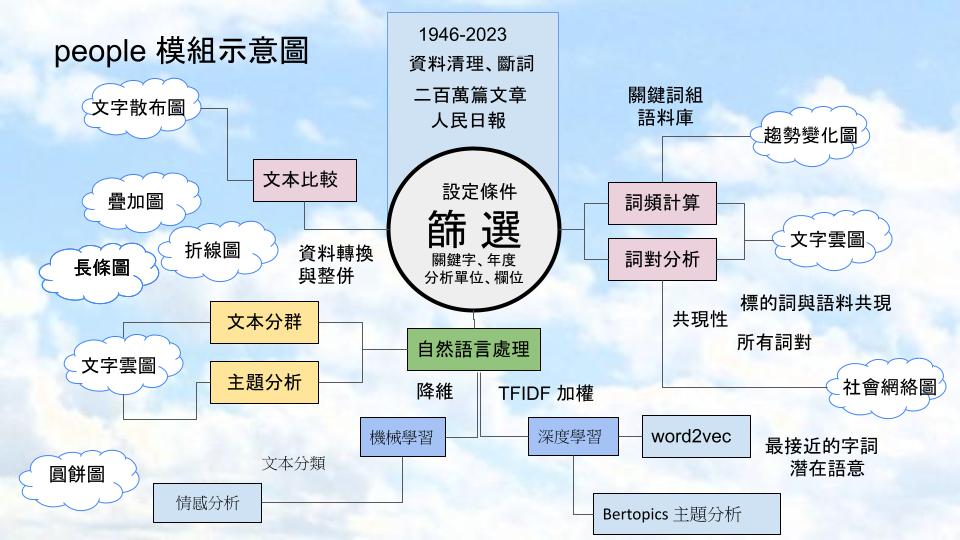
人民日報文字探勘研究網蒐集的人民日報文章,接近二百萬篇文章。如何使用這資料庫、進行分析並不容易。因為資料量龐大,必須仰賴電腦程式及各種演算法,從大量的文字中抽絲剝繭,找到背後的規則與現象。首先我們盤點用得到的演算法,在python, colab 的架構下,寫成副程式,降低初學者的進入門檻,提高分析的效率,在 colab 雲端平台上執行,非常方便。
我們開發的副程式,稱為 people 模組,其功能首先是資料篩選,設定不同的條件,篩選文本。接之下來詞頻計算,可以觀察趨勢變化。詞對分析,配合語料庫的運用,觀察共現性、繪製字詞的社會網絡圖。比較不同類型的文本,文字散布圖。自然語言處理是將字詞向量化,如此才可以使用電腦演算法。TFIDF 加權,降維是必頁的技巧,以便進行文本分群,主題分析,尋找字語的潛在語意。機械學習有助於文本分類,情感分析是其中的重點。深度學習,則最晚近突飛猛進的技術,文字探勘常用的有 word2vec, 以及 Bertopics 主題分析。以上這些方法,我們都寫成副程式,只要輸入參數、呼叫函數,即可得出結果。
people 模組的原始碼,大家可叫出修改,建構自己的模組。
應用範例,供大家參考。